This post written to address a confusing point in the documentation.
Let’s say you want to create a custom domain name for your Community based on the Napili template. You desire https://customers.foo.com.
Stumbling block number One
When enabling Communities in an org (and custom domains are only available in PROD), you get this screen:
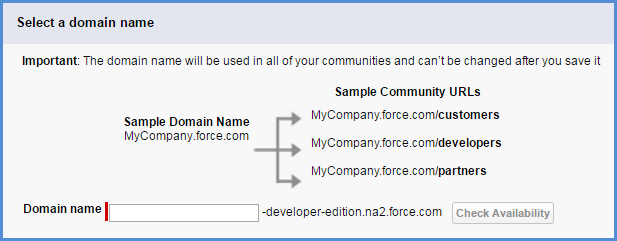
(screen shot is from Dev Edition so PROD will be slightly different in the default URL)
Your eyes feast on the “Important: The domain name will be used in all of your communities and can’t be changed after you save it”. But you want your community to be called customers.foo.com with no force.com in the domain at all. You get scared.
RELAX. Typically, you will use your company name, say foo, in the entry box. Think of this as the master URL for all your communities (up to 50) that Salesforce needs to host your communities. It isn’t until later that you will bind your Community to its custom domain and then to the master URL
Stumbling block number Two
When building a Community, say with the Napili template, where do you define the custom domain name?
ANSWER: You don’t. Just give your Community a good label to distinguish it from any other Communities you might create. The Community setup process prompts you for an optional suffix for your Community URL. And this URL uses a force.com domain as in foo.na2.force.com. Still not a custom domain. RELAX.
And here’s the secret sauce how it all comes together
Salesforce doesn’t make things easy with a wealth of terminology, some of which doesn’t seem to apply for the poor Napili template customizer. But the key thing to remember is that Napili-template Communities are Sites. That is, Sites with a capital S.
So step 1 to the Custom Domain (actually steps 1-4) are described in excellent detail in this Knowledge Article.
- Update your DNS Server With Your Custom Domain
- Create a Certificate Signing Request & Obtain an SSL Certificate for your domain
- Update your signed SSL certificate in Salesforce.
- Create a Custom Domain in Salesforce. Note that Communities has to be enabled in your PROD org to finish this step as you won’t be able to assign the certificate to the custom domain until Communities is enabled. Hence, previous comments above re: relaxing
At this point you are almost there. All that is left is binding your Community to the custom domain.
Go to Domains Management | Domains. The custom domain you created in step 4 above (customers.foo.com) will appear here with the attached certificate/key. Select the custom domain. Click New Custom URL.

The domain field is prepopulated as you would expect but what value goes into Site? Well, it is a lookup field so click the spyglass and, YES, you will see your Community in the list of available Sites. Select it and save. Your Community is now bound to the custom domain that is bound to the Community as hosted in Salesforce under a force.com domain name.
So, what’s happening under the hood?
- Your Community is hosted at Salesforce hence it has a force.com domain
- You define an alias in DNS (the CNAME entry) between your custom domain name and a domain name that Salesforce works with that includes your orgId. In this example,
customers.foo.com is aliased to customers.foo.com.yourorgId.live.siteforce.com. Full details on how CNAME works can be found in many places such as here.
- When your users visit
customers.foo.com the actual request via DNS goes to customers.foo.com.yourorgId.live.siteforce.com. Salesforce uses the binding between your custom domain and the Site (i.e. your published/activated Community) to find and render the pages of your community – the one you maintain in Community Builder. But the URL shown on the browser is what you want.
Pro tip:
Turns out you can migrate Communities from sandboxes to PROD with Changesets. Not every setting is copied but your pages will be. In the Changeset list of components, select Sites.com. A list of Communities will appear to choose from. See, knowing that Communities are Sites comes in handy.