Pardner, you sure got some ‘xplaining’ to do
In PROD, I had a daily REST query that executed against another SFDC org. It retrieved about 1000 or so Opportunities and had been executing just fine, night after night. But today, the Apex Jobs log showed ‘Read timed out’. In fact, three days’ worth – ouch.
First thought – timeout argument too low
Perhaps the timeout needed to be bumped up in the HTTPRequest call?
This wasn’t it, I was using this Apex to set the timeout:
hRqst.setTimeout(120000); // max is 120 secs = 120000 ms
Second thought, the REST SOQL query needed optimization
Of course, I wanted to deny this possibility as the REST query had been running along just fine for weeks now. But what if the target (of the query) SFDC org had gotten much bigger and this was causing the query to slow down. After all, the target org (not managed by me) actually has hundreds of thousands of Opportunities but I thought I was using an index so why would there be a problem?
Let’s take a look at the query (simplified) for discussion purposes:
select id, stageName,
(select unitPrice, totalPrice, pricebookEntry.name from OpportunityLineItems)
from Opportunity where closedate >= THIS_QUARTER and ID IN
(select opportunityId from opportunityLineItem
where pricebookEntry.name = 'FOO' OR
(bar__c = 'BAR' and is_Active__c = true))
You can see that the query does a semi-join – it is looking for Opportunities where at least one Opportunity Product meets some criteria.
Now, distant genetic memory kicked in and I remembered that SFDC introduced Query Plan explains back in V30. I hadn’t had a reason to look at this as I wasn’t experiencing any performance issues until now.
Using SFDC Workbench REST Explorer, I logged into the target SFDC org (the one where the query executes). I created this REST GET:
/services/data/v32.0/query?explain=select+id+(select++unitPrice,+totalPrice,pricebookEntry.name+from+OpportunityLineItems)++from+Opportunity+where+closedate+>=+THIS_QUARTER+and+ID+IN+(select+opportunityId+from+opportunityLineItem++where+pricebookEntry.name+=+'FOO'+OR+(bar__c+=+'BAR'+and+is_active__c+=+true))
And here was the result – three possible plans, the first one has a relative cost of < 1.0 so it meets the 'selective query definition'. It will use an index.
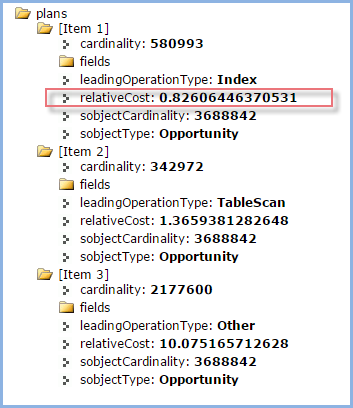
So, although 0.826 isn’t great, there are over 500,000 records to consider. So why was the query timing out?
Third thought – The Explain feature doesn’t consider the semi-join portion
Since there are really two queries being executed and joined together, I hypothesized that the query on OpportunityLineItem wasn’t ‘explained’. So, I decided to see what that query would look like ‘explained’. Back to REST Explorer and I entered this:
/services/data/v32.0/query?explain=select+opportunityId+from+opportunityLineItem++where+(pricebookEntry.name+=+'FOO'+OR+(bar__c+=+'BAR'+and+is_active__c+=+true))
And the plan (only one) came back being a table scan of 2.1 million rows! Uh-oh. Here was the problem. As you might suspect, the culprit is the OR clause on non-indexed custom fields.
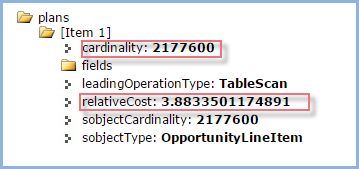
So, how to make this query use an index? I had naively thought (or perhaps it was epistemic arrogance) that SFDC would automatically exclude any OpportunityLineItem that was prior to the current quarter as specified by the semi-join’s left hand query; and I knew closeDate was indexed. Wrong!
So, I added into the semi joins right hand query a condition to only include OpportunityLineItem whose parent Opportunity’s closeDate was in the current quarter or beyond:
/services/data/v32.0/query?explain=select+opportunityId+from+opportunityLineItem++where+opportunity.closeDate+>=+THIS_QUARTER+and+(pricebookEntry.name+=+'FOO'+OR+(bar__c+=+'BAR'+and+is_active__c+=+true))
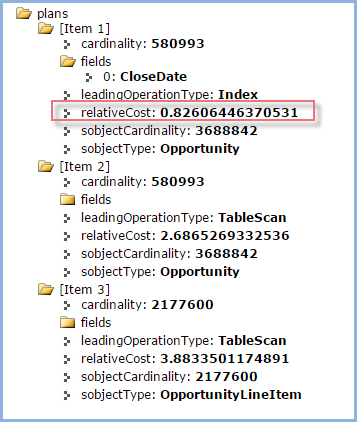
The explain’s relative cost for this optimization now falls below 1.0 and hence it too will use an index. The semi join will join the results of two index result sets.
Peace
I adjusted the daily job’s query using the properly selective semi-join right hand side and reran the daily job. No more timeout!
Update! – after writing all this, I learned I could access the Query Plan from the Developer Console. I tend to avoid using that on orgs I don’t control for fear of writing some anonymous Apex by mistake or using DML through the Query Editor results.
Resources
SFDC KB article (using Developer Console)
Using REST explain